struct klist_node {
void *n_klist; /* never access directly */
struct list_head n_node;
struct kref n_ref;
}/**
* list_replace - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
/**
* list_replace_init - replace old entry by new one and initialize the old one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace_init(struct list_head *old,
struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);
}/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}< include/linux/klist.h>, < include/linux/list.h>에 있는 커널 분석을 진행하며 리눅스 링크드 리스트 구조에 대한 이해를 해보자!
아마도 doubly linked list 방식을 사용하고 있는 것 같다.
struct klist {
spinlock_t k_lock;
struct list_head k_list;
void (*get)(struct klist_node *);
void (*put)(struct klist_node *);
} __attribute__ ((aligned (sizeof(void *))));
k_lock : mutex를 보장하기 위한 lock
list_head : linked list의 head node
*get, *put : 노드를 넣고, 빼는 함수 포인터
extern void klist_init(struct klist *k, void (*get)(struct klist_node *),
void (*put)(struct klist_node *));
위처럼 init 함수를 통해서 linked list structure를 선언할 수 있다
따로 alloc 하지 않아도 되고, klist 포인터를 전달해주고 해당 리스트의 get, put의 함수 포인터를 전달해주면 됨
함수 내에서 LIST_HEAD_INIT을 통해서 initialize를 수행한다.
// <linux/include/list.h> 에서 LIST_HEAD_INIT을 확인할 수 있다.
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
WRITE_ONCE(list->prev, list);
}
// tools/include/compiler.h에서 WRITE_ONCE 함수를 확인할 수 있다.
#define WRITE_ONCE(x, val) \
({ \
union { typeof(x) __val; char __c[1]; } __u = \
{ .__val = (__force typeof(x)) (val) }; \
__write_once_size(&(x), __u.__c, sizeof(x)); \
__u.__val; \
})
static __always_inline void __write_once_size(volatile void *p, void *res, int size)
{
switch (size) {
case 1: *(volatile __u8_alias_t *) p = *(__u8_alias_t *) res; break;
case 2: *(volatile __u16_alias_t *) p = *(__u16_alias_t *) res; break;
case 4: *(volatile __u32_alias_t *) p = *(__u32_alias_t *) res; break;
case 8: *(volatile __u64_alias_t *) p = *(__u64_alias_t *) res; break;
default:
barrier();
__builtin_memcpy((void *)p, (const void *)res, size);
barrier();
}
}WRITE_ONCE 함수를 살펴보면 2가지 변수, x와 val을 받는다.
typeof(x) __val, char __c[1]을 변수로 가지는 union 공용체 __u를 선언한다.
__val은 x와 같은 타입의 변수를 갖는데 해당 변수에 입력받은 val 값을 강제로 x의 typeof로 형변환을 한 값을 저장한다.
그리고 __write_once_size로 에 값을 써주는데 해당 operation을 확인하면 x의 주소에 __u.__c의 값을 넣어준다. 이때 __u는 union이기 때문에 결국 __u.__c는 실질적으로 x와 같은 값을 가지고 있다.
그리고 write_once_size를 보면 1,2,4,8에 해당하는 size는 volatile로 최적화 과정에서 형변환이 일어나지 않도록 캐스팅을 해주고, 만약 해당 사이즈가 아니라면 barrier를 통해서 연산 순서를 강제하고 있다. 즉 builtin_memcpy가 일어나기 전에 있는 모든 메모리 접근 함수가 완료되었음을 보장하고 그 두번째 barrier는 bullitin_memcpy가 끝난 이후에 메모리 접근이 순서대로 일어나도록 보장한다.
해당 함수를 통해 WRITE를 atomically하게 수행할 수 있다
(이것도 아마 멀티 쓰레딩에서 atomic operation을 보장하기 위한 하나의 테크닉으로 볼 수 있을 듯 하다 )
2. list_add
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
linked list의 꼬리에 node를 새로 추가하는 것을 볼 수 있다.
WRITE_ONCE(prev->next, new); 를 통해서 해당 함수 add하는 동작이 atomic하게 연결되는 것을 확인할 수 있다.
new->next, new->prev를 연결하는 것은 atomic하게 되지 않아도 된다는걸 안다 ( 어차피 새로운 데이터니까 )
근데 next->prev를 연결할 땐 왜 atomic하게 하지 않을까??
이유는 __list__add__valid에 있었다!!
/*
* Performs list corruption checks before __list_add(). Returns false if a
* corruption is detected, true otherwise.
*
* With CONFIG_LIST_HARDENED only, performs minimal list integrity checking
* inline to catch non-faulting corruptions, and only if a corruption is
* detected calls the reporting function __list_add_valid_or_report().
*/
static __always_inline bool __list_add_valid(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
bool ret = true;
if (!IS_ENABLED(CONFIG_DEBUG_LIST)) {
/*
* With the hardening version, elide checking if next and prev
* are NULL, since the immediate dereference of them below would
* result in a fault if NULL.
*
* With the reduced set of checks, we can afford to inline the
* checks, which also gives the compiler a chance to elide some
* of them completely if they can be proven at compile-time. If
* one of the pre-conditions does not hold, the slow-path will
* show a report which pre-condition failed.
*/
if (likely(next->prev == prev && prev->next == next && new != prev && new != next))
return true;
ret = false;
}
ret &= __list_add_valid_or_report(new, prev, next);
return ret;
}
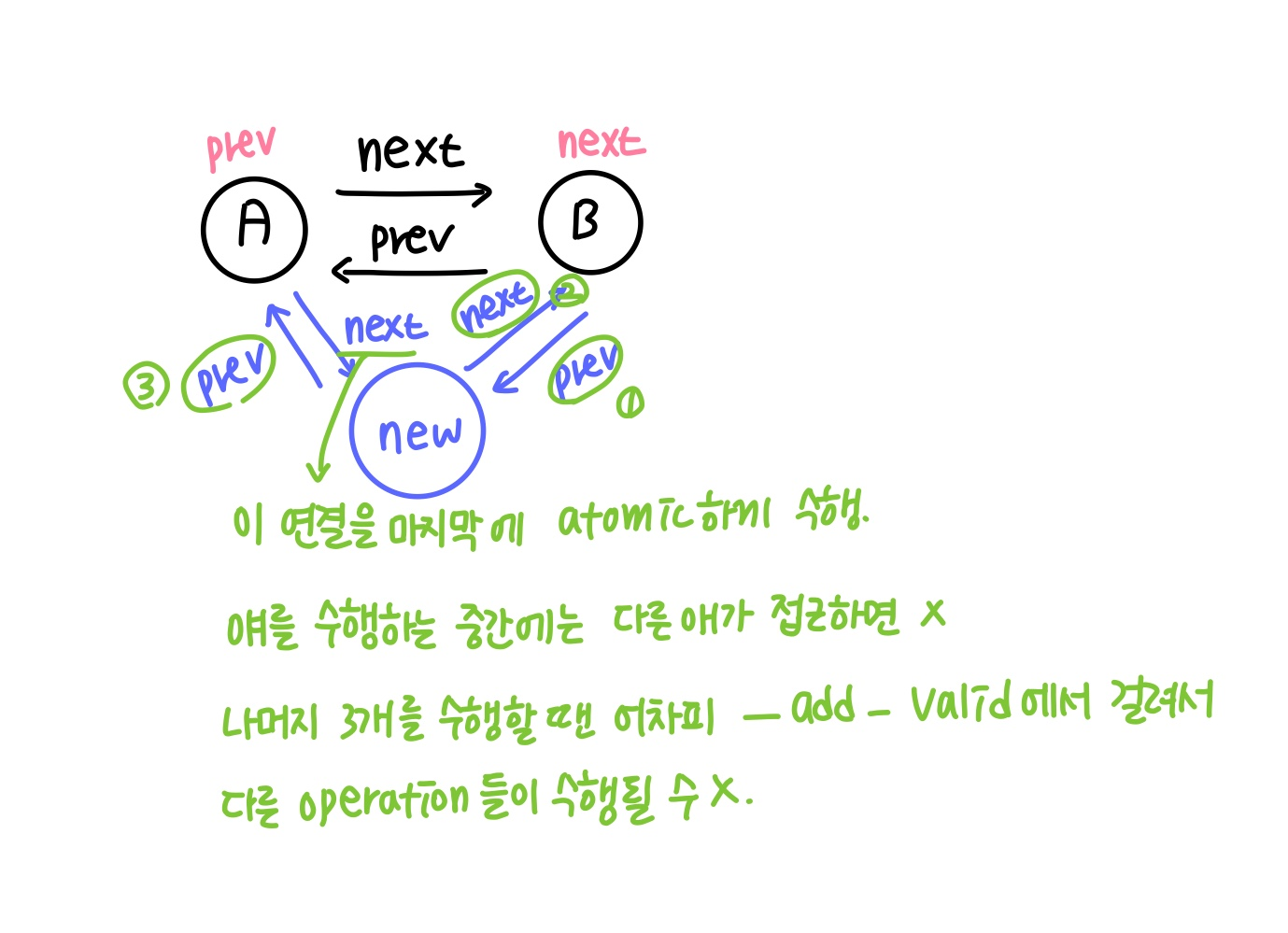
if문을 확인해보면 next->prev, prev, prev->next = next로 잘 연결이 되어있는지, 그리고 새로운 node에 연결이 안 되어 있는게 맞는지 체크를 해준다!
그니까 위에서도 마지막 prev->next = new 만 atomic하게 실행을 해주면 그 위에 operation들에서는 atomic하게 실행되지 않아도 다른 스레드에서 저 __list__add__valid에서 false 값이 반환되니까 그 operation은 이전 operation이 끝날때까지 실행되지 못한다!!
해당 __list_add 함수를 이용해
// list의 head에 데이터를 추가한다 > stack
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
// list의 tail에 데이터를 추가한다. > queue
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}이렇게 두 가지 메소드를 사용할 수 있다
3. list_del
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}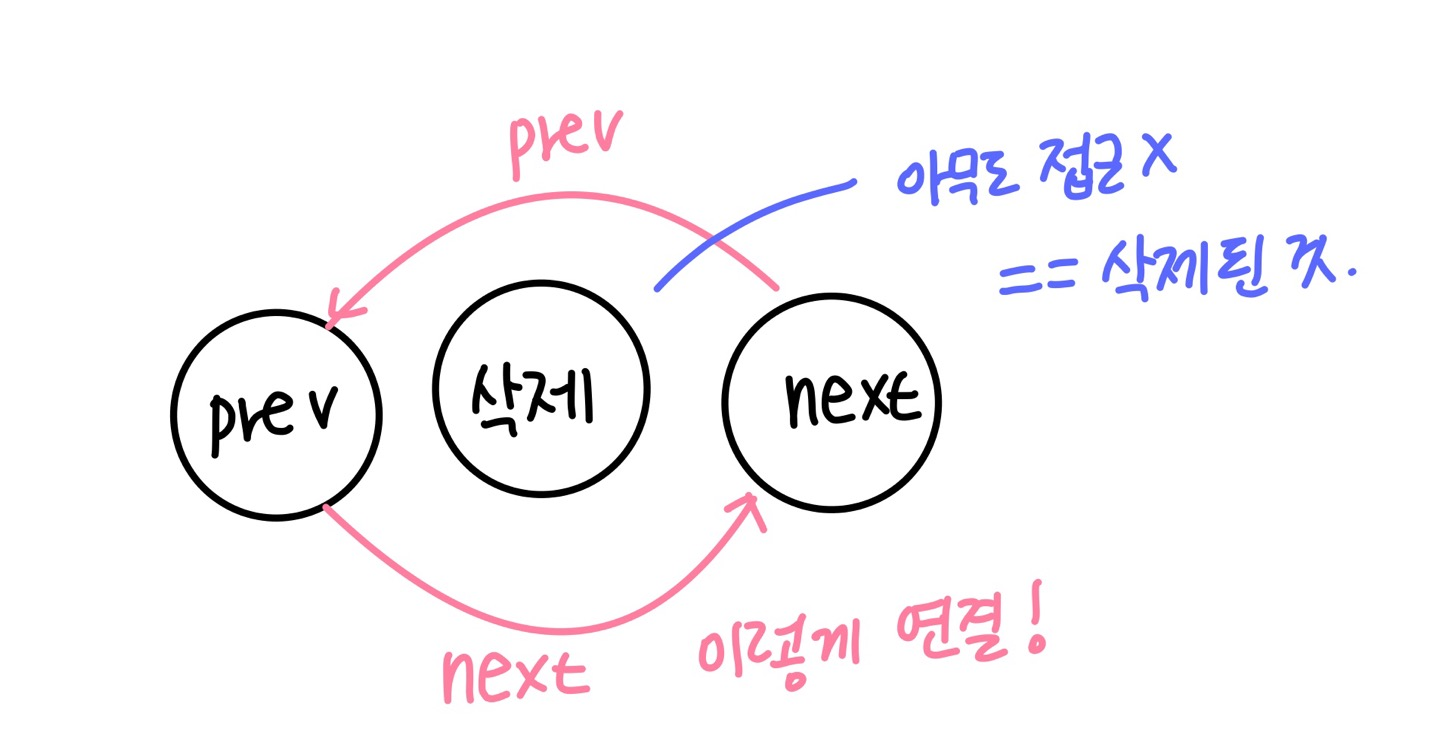
실제 다양한 list_del operation은 __list_del_entry로 수행이 되고 add와 같이 valid한지 수행하고 실제 delete를 수행하므로 prev->next = next만 atomic하게 실행이 되면 된다.
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
/*
* These are non-NULL pointers that will result in page faults
* under normal circumstances, used to verify that nobody uses
* non-initialized list entries.
*/
#define LIST_POISON1 ((void *) 0x100 + POISON_POINTER_DELTA)
#define LIST_POISON2 ((void *) 0x122 + POISON_POINTER_DELTA)list_del을 호출해서 해당 entry를 삭제할 수 있다
그럼 여기서 entry의 next, prev에 LIST_POISON을 왜 연결하는 걸까??
list del entry에서 지울 entry를 가리키는 포인터들은 없애줬지만, 해당 entry가 next, prev는 그대로 남아있다
이걸 LIST_POISON으로 초기화를 해서 해당 값을 접근을 하면 정상적인 상황임에도 PAGE_FAULT가 일어나도록 한다.
그렇게 하면 저런 초기화되지 않은 값에 접근하려는 사용자를 잡아낼 수 있다!
4. list_replace
/**
* list_replace - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
/**
* list_replace_init - replace old entry by new one and initialize the old one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace_init(struct list_head *old,
struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);
}
list_replace로 old 값을 new로 바꿔준다.
list_replace_init은 해당 list의 old>new로 바꿔주고 old의 prev, next가 모두 자기 자신을 가리키도록 해서 초기화를 해준다.
5. list_swap
/**
* list_swap - replace entry1 with entry2 and re-add entry1 at entry2's position
* @entry1: the location to place entry2
* @entry2: the location to place entry1
*/
static inline void list_swap(struct list_head *entry1,
struct list_head *entry2)
{
struct list_head *pos = entry2->prev;
list_del(entry2);
list_replace(entry1, entry2);
if (pos == entry1)
pos = entry2;
list_add(entry1, pos);
}list swap은 두 entry의 위치를 바꿔준다!

이런 로직으로 작동되는 듯 하다.
6. list_cut
/**
* list_cut_before - cut a list into two, before given entry
* @list: a new list to add all removed entries
* @head: a list with entries
* @entry: an entry within head, could be the head itself
*
* This helper moves the initial part of @head, up to but
* excluding @entry, from @head to @list. You should pass
* in @entry an element you know is on @head. @list should
* be an empty list or a list you do not care about losing
* its data.
* If @entry == @head, all entries on @head are moved to
* @list.
*/
static inline void list_cut_before(struct list_head *list,
struct list_head *head,
struct list_head *entry)
{
if (head->next == entry) {
INIT_LIST_HEAD(list);
return;
}
list->next = head->next;
list->next->prev = list;
list->prev = entry->prev;
list->prev->next = list;
head->next = entry;
entry->prev = head;
}
주어진 entry 이전까지 list를 반 잘라준다.
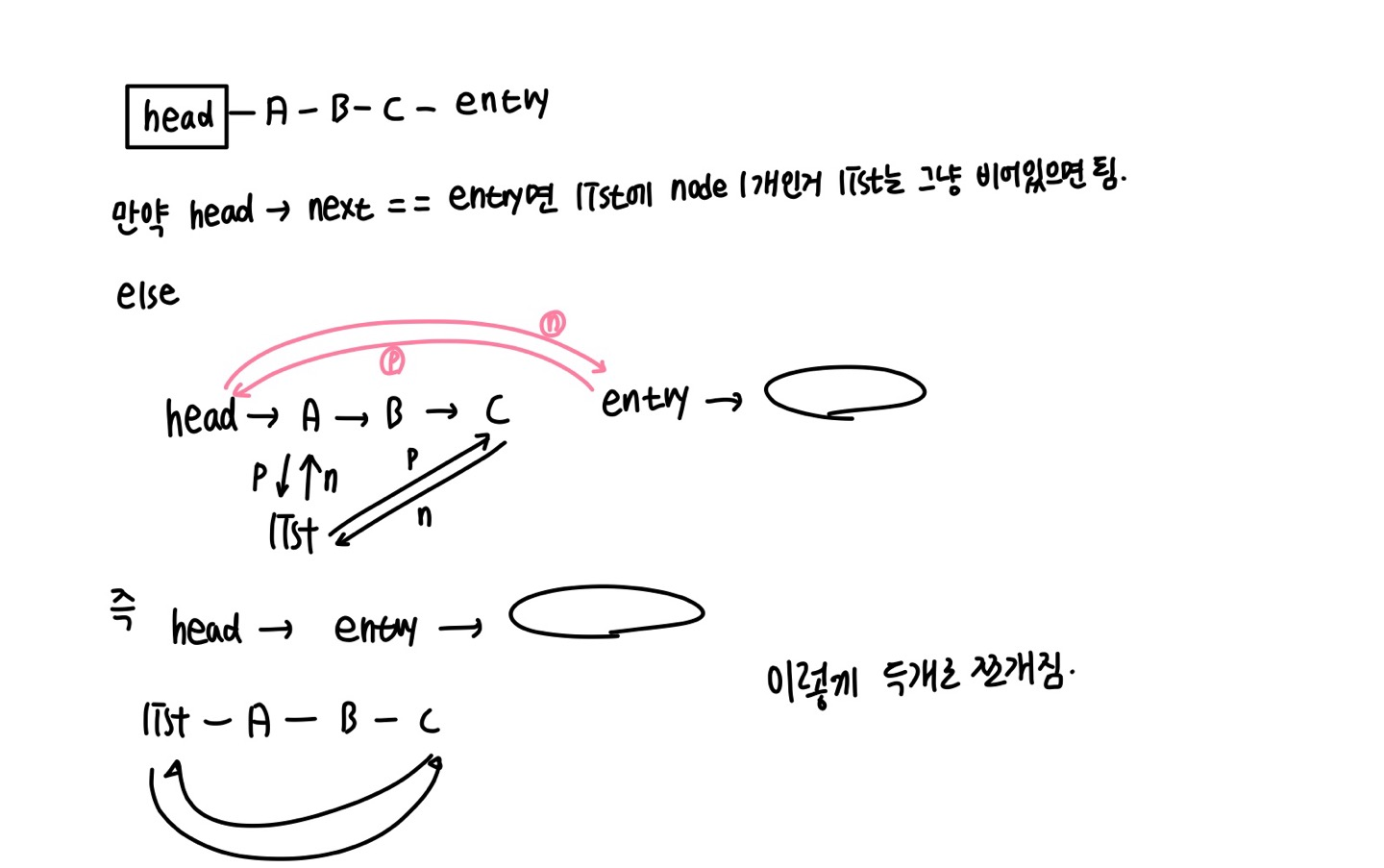
이런 식으로!!
7. list_spslice
static inline void __list_splice(const struct list_head *list,
struct list_head *prev,
struct list_head *next)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
first->prev = prev;
prev->next = first;
last->next = next;
next->prev = last;
}
/**
* list_splice - join two lists, this is designed for stacks
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice(const struct list_head *list,
struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head, head->next);
}
두 list를 합쳐준다.
list가 새로운 list가 되고
그 좌측, 우측에 각각의 list를 연결시켜서 합쳐준다
이 밖에도 list의 node의 갯수를 새는 함수
해당 entry의 struct를 가져오는 함수
등등 다양한 함수가 있다! 하지만 위의 함수를 기반으로 하는게 많고, 그렇게 어렵지 않은 내용이라 아마 사용하며 익힐 수 있을 듯 하다!
+) 실제 kernel code를 작성할 땐 <list.h>보단 <klist.h>를 많이 사용할 듯 하다
/* SPDX-License-Identifier: GPL-2.0-only */
/*
* klist.h - Some generic list helpers, extending struct list_head a bit.
*
* Implementations are found in lib/klist.c
*
* Copyright (C) 2005 Patrick Mochel
*/
#ifndef _LINUX_KLIST_H
#define _LINUX_KLIST_H
#include <linux/spinlock.h>
#include <linux/kref.h>
#include <linux/list.h>
struct klist_node;
struct klist {
spinlock_t k_lock;
struct list_head k_list;
void (*get)(struct klist_node *);
void (*put)(struct klist_node *);
} __attribute__ ((aligned (sizeof(void *))));
#define KLIST_INIT(_name, _get, _put) \
{ .k_lock = __SPIN_LOCK_UNLOCKED(_name.k_lock), \
.k_list = LIST_HEAD_INIT(_name.k_list), \
.get = _get, \
.put = _put, }
#define DEFINE_KLIST(_name, _get, _put) \
struct klist _name = KLIST_INIT(_name, _get, _put)
extern void klist_init(struct klist *k, void (*get)(struct klist_node *),
void (*put)(struct klist_node *));
struct klist_node {
void *n_klist; /* never access directly */
struct list_head n_node;
struct kref n_ref;
};
extern void klist_add_tail(struct klist_node *n, struct klist *k);
extern void klist_add_head(struct klist_node *n, struct klist *k);
extern void klist_add_behind(struct klist_node *n, struct klist_node *pos);
extern void klist_add_before(struct klist_node *n, struct klist_node *pos);
extern void klist_del(struct klist_node *n);
extern void klist_remove(struct klist_node *n);
extern int klist_node_attached(struct klist_node *n);
struct klist_iter {
struct klist *i_klist;
struct klist_node *i_cur;
};
extern void klist_iter_init(struct klist *k, struct klist_iter *i);
extern void klist_iter_init_node(struct klist *k, struct klist_iter *i,
struct klist_node *n);
extern void klist_iter_exit(struct klist_iter *i);
extern struct klist_node *klist_prev(struct klist_iter *i);
extern struct klist_node *klist_next(struct klist_iter *i);
#endifklist는 list structure와 klist_node structure가 분류되어 있다
그리고 list_head가 list의 head를 가리키고 여기에 실제 데이터는 저장되지 않는 것 같다.
struct klist_node {
void *n_klist; /* never access directly */
struct list_head n_node;
struct kref n_ref;
}k_list node는 이런식으로 생겼다
list_head : list.h에서 본 대로 next, prev를 가리키는 포인터가 저장되어있는 구조체
n_ref : reference count
n_klist : 해당 영역의 bit로 다양한 상태를 체크해서 operation을 수행
list와 klist의 차이가 있는 듯 한데, klist를 쓰는게 좀 더 낫지 않을까..
lock이나 이런게 구현이 되어있으서 thread-safe할 것 같다.
이런 list 구조체, 데이터를 같이 담은 struct를 선언해서 사용하는 것 같다 보통..
ref
https://wariua.github.io/facility/long-list-of-linked-lists.html
연결 리스트들의 긴 목록
리눅스 커널에는 연결 리스트 구현이 있다. 그것도 다양하게. 몇 가지를 살펴보자. 기본 첫 번째가 뭔지는 정해져 있다. include/linux/types.h: struct list_head { struct list_head *next, *prev; }; include/linux/list.h:
wariua.github.io